2026
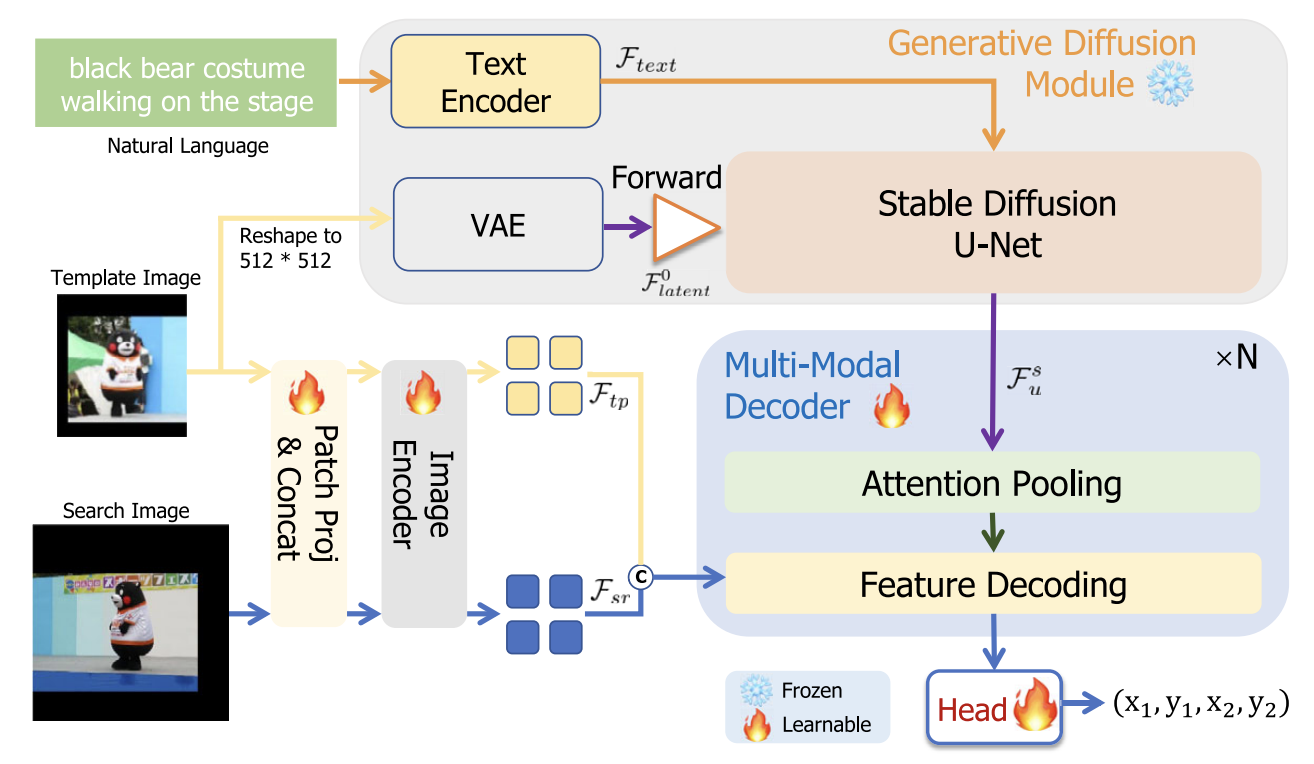
GLAD: Generative Language-Assisted Visual Tracking for Low-Semantic Templates
Xingyu Luo, Yidong Cai, Jie Liu, Jie Tang, Gangshan Wu, Limin Wang
International Journal of Computer Vision (IJCV-CCF A) 2026
Proposed GLAD, a generative language-assisted visual tracking framework that introduces a diffusion-based generative multimodal fusion paradigm to effectively integrate textual descriptions with low-semantic template images, enhancing cross-modal alignment and semantic representation, and achieving state-of-the-art performance on multiple benchmarks.
GLAD: Generative Language-Assisted Visual Tracking for Low-Semantic Templates
Xingyu Luo, Yidong Cai, Jie Liu, Jie Tang, Gangshan Wu, Limin Wang
International Journal of Computer Vision (IJCV-CCF A) 2026
Proposed GLAD, a generative language-assisted visual tracking framework that introduces a diffusion-based generative multimodal fusion paradigm to effectively integrate textual descriptions with low-semantic template images, enhancing cross-modal alignment and semantic representation, and achieving state-of-the-art performance on multiple benchmarks.